应用层
应用层概述
应用层的作用是为应用进程之间的通讯和交互制定规则。
HTTP 超文本传输协议
http 的特点
- 无状态:协议对客户端没有状态存储,对事物处理没有“记忆”能力,比如访问一个网站需要反复进行登录操作
- 无连接:HTTP/1.1 之前,由于无状态特点,每次请求需要通过 TCP 三次握手四次挥手,和服务器重新建立连接。比如某个客户机在短时间多次请求同一个资源,服务器并不能区别是否已经响应过用户的请求,所以每次需要重新响应请求,需要耗费不必要的时间和流量。
- 基于请求和响应:基本的特性,由客户端发起请求,服务端响应
- 简单快速、灵活
- 通信使用明文、请求和响应不会对通信方进行确认、无法保护数据的完整性
请求和响应报文
请求报文
- 第一行是请求方法、URL、版本协议
- 首部
- 空行分隔首部和主体
- 内容主体
GET http://www.example.com/ HTTP/1.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cache-Control: max-age=0
Host: www.example.com
If-Modified-Since: Thu, 17 Oct 2019 07:18:26 GMT
If-None-Match: "3147526947+gzip"
Proxy-Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 xxx
param1=1¶m2=2
响应报文
- 第一行是版本协议、状态码及描述
- 首部
- 空行分隔首部和主体
- 响应的主体
HTTP/1.1 200 OK
Age: 529651
Cache-Control: max-age=604800
Connection: keep-alive
Content-Encoding: gzip
Content-Length: 648
Content-Type: text/html; charset=UTF-8
Date: Mon, 02 Nov 2020 17:53:39 GMT
Etag: "3147526947+ident+gzip"
Expires: Mon, 09 Nov 2020 17:53:39 GMT
Keep-Alive: timeout=4
Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT
Proxy-Connection: keep-alive
Server: ECS (sjc/16DF)
Vary: Accept-Encoding
X-Cache: HIT
<!doctype html>
<html>
<head>
<title>Example Domain</title>
// 省略...
</body>
</html>
URL
URL 全称统一资源定位符,他是 URI(统一资源标识符)的子集,用于定位资源的路径。
HTTP 方法
GET 获取资源
POST 传送数据
DELETE 删除资源
PUT 上传文件。
由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法。
HEAD
PATCH 对资源进行部分修改
OPTIONS
CONNECT
TRACE
| http 方法 | 作用 | 备注 |
|---|---|---|
| get | 获取资源 | |
| post | 传送数据 | |
| delete | 删除文件 | 同样不带验证机制 |
| put | 上传文件 | 由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法。 |
| patch | 对资源进行部分修改 | |
| options | 查询支持的方法 | 会返回 Allow: GET, POST, HEAD, OPTIONS 这样的内容。常用于跨域请求 |
| head | 获取报文首部 | 和 get 类似,但不返回主体,主要用于确认 url 有效性及资源更新日期等 |
| connect | 要求在与代理服务器通信时建立隧道 | 使用 SSL(安全套接层)和 TLS(传输层安全)协议把通信内容加密后经网络隧道传输。 |
| trace | 追踪路径 | 服务器会将通信路径返回给客户端。 |
HTTP 状态码
| 状态码 | 类别 | 含义 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
- 1xx 信息
- 100 目前为止一切正常, 客户端应该继续请求
- 101 正在切换协议,常见 websocket
- 2xx 成功
- 200 请求成功
- 204 表示该请求已经成功了,但是客户端客户不需要离开当前页面
- 3xx 重定向
- 301 永久重定向
- 302 临时重定向
- 303 和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
- 304 服务端已经执行了 GET,但文件未变化,也就是说可以使用缓存的内容。
- 4xx 客户端错误
- 400 请求报文存在语法错误
- 403 请求被拒绝
- 404 资源不存在
- 500 服务器错误
- 500 服务器正在执行请求时发生错误
- 503 服务器暂时处于超负荷或停机维护
HTTP 首部
有 4 种类型的首部字段:通用首部字段、请求首部字段、响应首部字段和实体首部字段。
各种首部字段及其含义如下(不需要全记,仅供查阅):
通用首部字段
| 首部字段名 | 说明 |
|---|---|
| Cache-Control | 控制缓存的行为 |
| Connection | 控制不再转发给代理的首部字段、管理持久连接 |
| Date | 创建报文的日期时间 |
| Pragma | 报文指令 |
| Trailer | 报文末端的首部一览 |
| Transfer-Encoding | 指定报文主体的传输编码方式 |
| Upgrade | 升级为其他协议 |
| Via | 代理服务器的相关信息 |
| Warning | 错误通知 |
请求首部字段
| 首部字段名 | 说明 |
|---|---|
| Accept | 用户代理可处理的媒体类型 |
| Accept-Charset | 优先的字符集 |
| Accept-Encoding | 优先的内容编码 |
| Accept-Language | 优先的语言(自然语言) |
| Authorization | Web 认证信息 |
| Expect | 期待服务器的特定行为 |
| From | 用户的电子邮箱地址 |
| Host | 请求资源所在服务器 |
| If-Match | 比较实体标记(ETag) |
| If-Modified-Since | 比较资源的更新时间 |
| If-None-Match | 比较实体标记(与 If-Match 相反) |
| If-Range | 资源未更新时发送实体 Byte 的范围请求 |
| If-Unmodified-Since | 比较资源的更新时间(与 If-Modified-Since 相反) |
| Max-Forwards | 最大传输逐跳数 |
| Proxy-Authorization | 代理服务器要求客户端的认证信息 |
| Range | 实体的字节范围请求 |
| Referer | 对请求中 URI 的原始获取方 |
| TE | 传输编码的优先级 |
| User-Agent | HTTP 客户端程序的信息 |
响应首部字段
| 首部字段名 | 说明 |
|---|---|
| Accept-Ranges | 是否接受字节范围请求 |
| Age | 推算资源创建经过时间 |
| ETag | 资源的匹配信息 |
| Location | 令客户端重定向至指定 URI |
| Proxy-Authenticate | 代理服务器对客户端的认证信息 |
| Retry-After | 对再次发起请求的时机要求 |
| Server | HTTP 服务器的安装信息 |
| Vary | 代理服务器缓存的管理信息 |
| WWW-Authenticate | 服务器对客户端的认证信息 |
实体首部字段
| 首部字段名 | 说明 |
|---|---|
| Allow | 资源可支持的 HTTP 方法 |
| Content-Encoding | 实体主体适用的编码方式 |
| Content-Language | 实体主体的自然语言 |
| Content-Length | 实体主体的大小 |
| Content-Location | 替代对应资源的 URI |
| Content-MD5 | 实体主体的报文摘要 |
| Content-Range | 实体主体的位置范围 |
| Content-Type | 实体主体的媒体类型 |
| Expires | 实体主体过期的日期时间 |
| Last-Modified | 资源的最后修改日期时间 |
短连接与长连接
当浏览器访问一个包含多张图片的 HTML 页面时,除了请求访问的 HTML 页面资源,还会请求图片资源。如果每进行一次 HTTP 通信就要新建一个 TCP 连接,那么开销会很大。
长连接只需要建立一次 TCP 连接就能进行多次 HTTP 通信。
- 从 HTTP/1.1 开始默认是长连接的,如果要断开连接,需要由客户端或者服务器端提出断开,使用
Connection : close; - 在 HTTP/1.1 之前默认是短连接的,如果需要使用长连接,则使用
Connection : Keep-Alive。
Cookie
HTTP 协议是无状态的,主要是为了让 HTTP 协议尽可能简单,使得它能够处理大量事务。HTTP/1.1 引入 Cookie 来保存状态信息。
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API(本地存储和会话存储)或 IndexedDB。
用途
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
创建过程
服务器发送的响应报文包含 Set-Cookie 首部字段,客户端得到响应报文后把 Cookie 内容保存到浏览器中。
str客户端之后对同一个服务器发送请求时,会从浏览器中取出 Cookie 信息并通过 Cookie 请求首部字段发送给服务器。
str分类
- 会话期 Cookie:浏览器关闭之后它会被自动删除,也就是说它仅在会话期内有效。
- 持久性 Cookie:指定过期时间(Expires)或有效期(max-age)之后就成为了持久性的 Cookie。
str作用域
Domain 标识指定了哪些主机可以接受 Cookie。如果不指定,默认为当前文档的主机(不包含子域名)。如果指定了 Domain,则一般包含子域名。例如,如果设置 Domain=mozilla.org,则 Cookie 也包含在子域名中(如 developer.mozilla.org)。
Path 标识指定了主机下的哪些路径可以接受 Cookie(该 URL 路径必须存在于请求 URL 中)。以字符 %x2F (“/”) 作为路径分隔符,子路径也会被匹配。例如,设置 Path=/docs,则以下地址都会匹配:
- /docs
- /docs/Web/
- /docs/Web/HTTP
JavaScript
浏览器通过 document.cookie 属性可创建新的 Cookie,也可通过该属性访问非 HttpOnly 标记的 Cookie。
strHttpOnly
标记为 HttpOnly 的 Cookie 不能被 JavaScript 脚本调用。跨站脚本攻击 (XSS) 常常使用 JavaScript 的 document.cookie API 窃取用户的 Cookie 信息,因此使用 HttpOnly 标记可以在一定程度上避免 XSS 攻击。
strSecure
标记为 Secure 的 Cookie 只能通过被 HTTPS 协议加密过的请求发送给服务端。但即便设置了 Secure 标记,敏感信息也不应该通过 Cookie 传输,因为 Cookie 有其固有的不安全性,Secure 标记也无法提供确实的安全保障。
Session
除了可以将用户信息通过 Cookie 存储在用户浏览器中,也可以利用 Session 存储在服务器端,存储在服务器端的信息更加安全。
Session 可以存储在服务器上的文件、数据库或者内存中。也可以将 Session 存储在 Redis 这种内存型数据库中,效率会更高。
使用 Session 维护用户登录状态的过程如下:
- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
- 服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
- 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
应该注意 Session ID 的安全性问题,不能让它被恶意攻击者轻易获取,那么就不能产生一个容易被猜到的 Session ID 值。此外,还需要经常重新生成 Session ID。在对安全性要求极高的场景下,例如转账等操作,除了使用 Session 管理用户状态之外,还需要对用户进行重新验证,比如重新输入密码,或者使用短信验证码等方式。
HTTP 缓存
页面第一次加载时,会将资源进行缓存,在过期之前再次请求该资源,则会直接使用缓存,而不会重新发送请求,这样有利于节省资源和加快速度。
http 缓存分为强缓存和协商缓存。
强缓存
在缓存资源过期之前再次请求,则会使用强缓存。
强缓存通过expires和cache-control控制资源过期时间,cache-control的优先级高于expires。
cache-control接收的值有
- max-age: value 设置过期时间,表示多少 s 后过期
- no-store 不使用缓存
- no-cache 缓存,但是每次都要向服务器验证
- private 响应只能被客户端缓存
- public 响应可以被任意缓存
协商缓存
当超过过期时间之后再请求缓存资源时,则会向服务器协商,客户端将缓存标识传给服务器,服务器拿着资源标识去匹配,如果资源没有更新,则返回 304 状态码并重新设置过期时间,客户端会读取本地缓存;如果不匹配,则表示资源有更新,服务器将新数据和新的资源标识一起返回给客户端。
发送需要发送资源标识和最后修改时间,但是服务器发给客户端的和客户端发给服务器都要这两个字段,因此共有这四个字段,两两出现。
- etag 资源唯一标识
- last-modified 最后修改时间
- if-None-Match 客户端缓存资源标识
- if-Modified-Since 客户端发送给服务器的资源最后修改时间
HTTPS
HTTPS 基于 HTTP,通过 SSL 或 TLS 提供加密处理数据、验证对方身份以及数据完整性保护功能。
**HTTPS = HTTP + SSL 协议或 TLS 协议。**也就是说 https 本质上是基于 http 协议的,只不过增加了一个安全层(SSL 协议或 TLS 协议)。
HTTPS 的目的是解决 http 传输过程中不安全的问题,简单来说它解决了三件事:
- 数据明文传输,易泄露隐私
- 无法对服务器进行身份认证。
- 数据传输过程中易被篡改
加密
解决数据泄露的最好方式是对数据进行加密。https 使用了公钥加密和对称密钥加密结合的方式来加密数据,保证数据不会在传输过程中泄露信息。
公钥加密是服务器将公钥传给客户端,而私钥自己保存,客户端拿到公钥后对数据进行加密,然后发送到服务器上,只有服务器的私钥才能解密,也就是说只要服务器的私钥不泄露,安全性还是很高的。
对称加密是加密和解密都是同一个密钥,这种方式效率比较高,但是有个很大的问题,就是如何将密钥传给客户端,如果直接传输,那么就会很容易造成密钥泄露,那么加密就形同虚设了。
公钥加密的特点是安全性高,但是效率低,而对称密钥加密的特点是效率高,但是安全性低。
https 利用了两者的特点,先用公钥加密的方式将密钥传给客户端,这样解决了密钥泄露的风险,然后双方再使用对称密钥的方式进行加密通讯。
身份认证
https 通过数字证书来解决身份认证的问题。
第三方权威机构,对服务器进行认证,然后对服务器的公开密钥进行数字签名,并且将此公钥放入到为此服务器颁发的数字证书之中。
当客户端请求 https 时,服务器只需将数字证书发送给客户端,客户端可以通过数字证书进行认证,数字证书有两个作用。
- 一是数字证书是经过权威机构加密过的,浏览器中内置解密密钥,同时数字证书难以伪造,因此将服务器公钥放入数字证书中可以避免公钥被篡改或者替换。
- 二是客户端可以通过数字证书来对服务器进行身份认证,判断该服务器是否可以信赖。
避免篡改
HTTPS 在发送数据时会附加一种叫做 MAC(消息身份验证码)的报文摘要,MAC 能够查知报文是否遭到篡改,从而保护报文的完整性。
HTTPS 握手流程
可以分为三步: 密钥协商、认证、加密
- 双发“协商”要使用的加密组件和 SSL(或 TLS)版本
- 服务器发送数字证书,客户端进行验证,并且从中去除公钥
- 客户端用取出来的公钥加密随机密码串,并发送服务器,服务器接收后用私钥解密,然后双发使用随机密码串来进行对称密钥加密通讯。
具体步骤
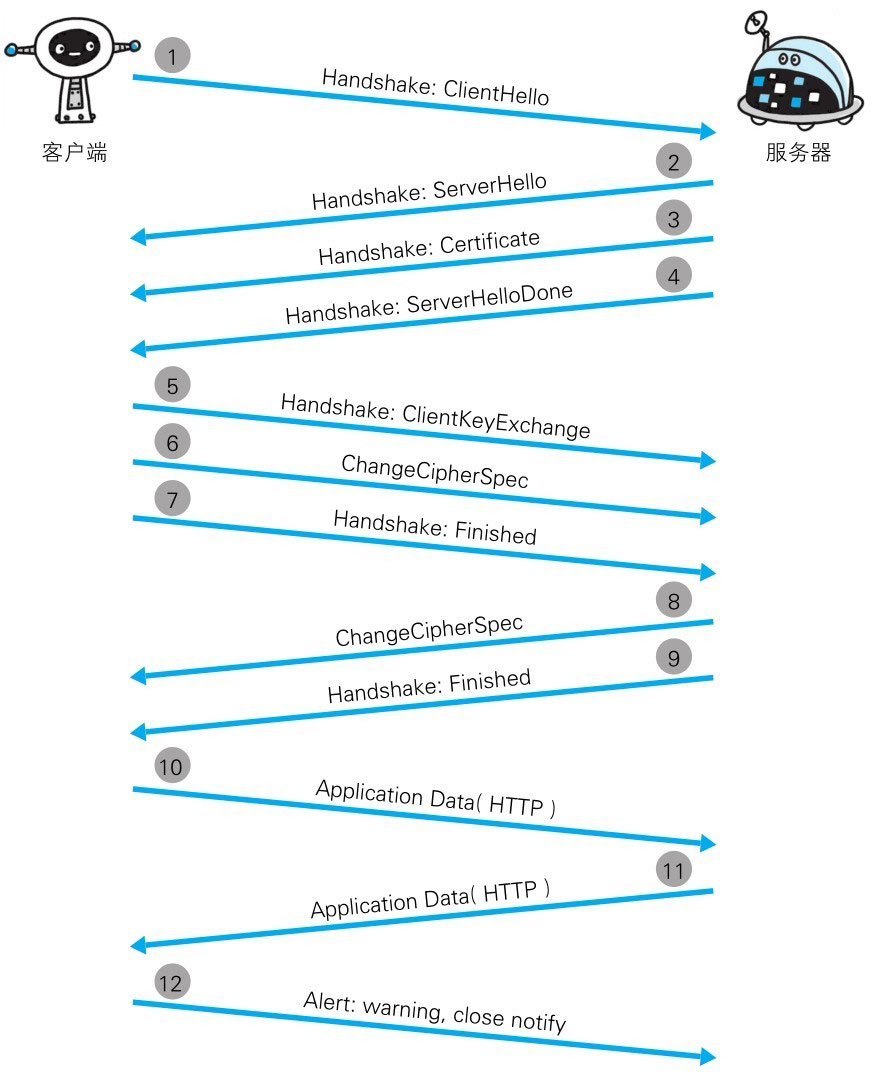
步骤 1: 客户端通过发送 Client Hello 报文开始 SSL 通信。报文中包含客户端支持的 SSL 的指定版本、加密组件(Cipher Suite)列表(所使用的加密算法及密钥长度等)。步骤 2: 服务器可进行 SSL 通信时,会以 Server Hello 报文作为应答。和客户端一样,在报文中包含 SSL 版本以及加密组件。服务器的加密组件内容是从接收到的客户端加密组件内筛选出来的。步骤 3: 之后服务器发送 Certificate 报文。报文中包含公开密钥证书。步骤 4: 最后服务器发送 Server Hello Done 报文通知客户端,最初阶段的 SSL 握手协商部分结束。步骤 5: SSL 第一次握手结束之后,客户端以 Client KeyExchange 报文作为回应。报文中包含通信加密中使用的一种被称为 Pre-master secret 的随机密码串。该报文已用步骤 3 中的公开密钥进行加密。步骤 6: 接着客户端继续发送 Change Cipher Spec 报文。该报文会提示服务器,在此报文之后的通信会采用 Pre-master secret 密钥加密。步骤 7: 客户端发送 Finished 报文。该报文包含连接至今全部报文的整体校验值。这次握手协商是否能够成功,要以服务器是否能够正确解密该报文作为判定标准。步骤 8: 服务器同样发送 Change Cipher Spec 报文。步骤 9: 服务器同样发送 Finished 报文。步骤 10: 服务器和客户端的 Finished 报文交换完毕之后,SSL 连接就算建立完成。当然,通信会受到 SSL 的保护。从此处开始进行应用层协议的通信,即发送 HTTP 请求。步骤 11: 应用层协议通信,即发送 HTTP 响应。步骤 12: 最后由客户端断开连接。断开连接时,发送 close_notify 报文。上图做了一些省略,这步之后再发送 TCP FIN 报文来关闭与 TCP 的通信。
HTTP2
HTTP2 的目标是提高传输性能。
http2 的特点
- 多路复用
- 二进制协议
- 首部压缩
- 流的优先级
- 流量控制
- 服务器推送
二进制协议
http1.1 是基于文本的,而 http2 则是基于二进制的,http 消息被定义成数据帧发送。
多路复用
http1.1 是一种同步的、请求-响应式的协议,一条连接中当发送一条请求后,需要等待接收完响应后才能发送另一条请求,这种方式效率低下。
而 http2 实现了多路复用,即允许单条连接上同时执行多条请求。
http2 通过使用二进制分帧层,将一条请求或响应封装成帧,并标上一个流(消息)的标识符,发送方可以将多条请求同时发送出去,当接收方接收一条流的所有帧后,可以将帧合成完整的消息。
http2 提高效率的重点在于他不用等待响应接收后才能发送下一个请求,而是可以变接收响应边发送请求,这样的效率更高。
Get 与 Post 的区别
- get 方法如果不改变 url,可能会存在缓存问题,一般会在后面加上时间戳来重新加载。
- get 请求参数是放在 url 中,而 post 参数是放到请求体里。
- post 方式请求时,需要设置编码类型,一般是在请求头里的
content-type里设置,值有application/x-www-form-urlencoded、application/json、multipart/formdata等格式。 - get 主要是用作获取数据,而 post 是修改数据
- get 的参数是放到 url 中,也就是说参数的长度取决于浏览器的 url 限制长度。
DNS 域名系统
DNS 全称域名系统,他的作用是实现 ip 地址与域名的互转。
DNS 传输使用的是 UDP,这样能减少性能开销,此外域名服务器还设有缓存,会将查询结果缓存一定时间,来减少查询次数。
域名系统查询过程(迭代)
- 浏览器将域名发送给本地域名服务器,并成为本地域名服务器的一个客户
- 本地域名服务器查询根域名服务器,根域名服务器给出下一步要查询的域名服务器
- 本地域名服务器查询顶级域名服务器,顶级域名服务器给出下一步要查询的域名服务器
- 本地域名服务器查询二级域名服务器,二级域名服务器给出下一步要查询的域名服务器
- …
- 本地服务器查询权限域名服务器,并获取主机的 ip 地址
- 本地域名服务器将查询结果告诉主机
域名系统查询过程(递归)
- 浏览器将域名发送给本地域名服务器,并成为本地域名服务器的一个客户
- 本地域名服务器查询根域名服务器
- 根域名查询顶级域名服务器
- 顶级域名服务器查询二级域名服务器
- 二级域名服务器查询权限域名服务器
- 权限域名服务器查询到主机的 ip 地址,并将结果返回给二级域名服务器
- 二级域名服务器将查询结果返回给顶级域名服务器
- 顶级域名服务器将查询结果返回给跟域名服务器
- 根域名服务器将查询结果返回给本地域名服务器
- 本地域名服务器将查询结果返回给主机
CDN
CDN是指内容分发网络,CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上,从而达到加快访问速度的目的。
CND的工作原理
CDN查询过程:
- 客户端本地DNS系统解析,如果没有相应域名的缓存,则本地DNS系统会将域名解析权交给CNAME指向的CDN的专用DNS服务器。
- CDN的DNS服务器返回全局负载均衡设备的ip地址
- 用户将CDN的全局负载均衡设备发起请求。
- 全局负载均衡设备根据用户的ip地址及请求url,选择一台用户所属区域的区域负载均衡设备,并将请求转发到此设备上。
- 区域负载均衡设备根据用户的ip地址、请求url及各缓存服务器的负载情况,选择出一台最佳的缓存服务器,并将此缓存服务器的ip地址返回给全局负载均衡设备
- 全局负载均衡设备将缓存服务器的ip地址返回给客户端。
- 客户端向缓存服务器发送请求,缓存服务器响应请求。如果服务器没有请求的资源,则会向上一级缓存服务器请求内容,直至追溯到向源服务器发送请求将资源拉取到本地。
CDN的优缺点
优点
- 解决了跨运营商、跨地区所带来的的访问慢的问题,加快资源的访问速度。
- 资源访问是通过缓存服务器而不是源服务器,在一定程度上避免了源服务器被攻击的风险。
缺点
- 贵